
Prioritizing Time to Value
At Hyperscience, we take pride in our continuous innovation on behalf of our customers. It’s how we’ve been able to provide an AI/ML platform that solves for challenging use-cases, and it’s how we go about implementing new features that provide tangible business value.
In our more recent efforts, we’ve prioritized reducing time-to-value (TTV) so that customers can start seeing results on our platform even faster. By reducing TTV, even by just a bit, we’re helping organizations increase productivity, and we’re making it easier than ever for users to onboard with the platform.
At the same time, we wanted to make it possible for our sales engineers to create demos that require fewer documents, less model training, and fewer flow customizations for well-established use cases.
The Backstory
Building on the research titled OCR-free Document Understanding with Donut, our ML team began researching No-OCR Document Understanding models in order to simplify our ML pipeline. Beyond observing the simplified document extraction pipelines, we were excited to discover just how much these models improved processing speed, while retaining our best in class accuracy and automation.
To put this new model to the test, we decided to use the Donut Model for a series of out-of-the-box solutions, applying them to common use cases that we’ve observed in most of our customer’s business processes.
Applying the Donut Model to Out-Of-The-Box Solutions
We first focused on the critical documents used in business processes prevalent to many of our customers—processes like KYC (Know Your Customer), account creation, and invoice processing. In particular, we developed No-OCR models for four document types: passports, checks, driver’s licenses, and invoices.

For these four document types, customers can now extract a broad list of common fields without providing any of their own training samples. As a result, users can realize value from the platform sooner, and can focus on building/optimizing models to achieve higher ROI from their automation.
You can see these models in action in the demo below:
How does the Donut model work?
Traditionally, document understanding tasks involved pre-processing steps that would yield a series of transcribed segments with locations. Donut, on the other hand, is a visual document understanding (VDU) model that receives only an image of a document and a prompt with details of the understanding task to generate (i.e. Generative AI) a desired response.
The model architecture itself is composed of a visual encoder (Swin transformer) and text decoder (Bart) that has been pre-trained on a full-page transcription task. While multi-modal LLMs (like GPT-4) generate arbitrary, instruction-tuned text, Donut generates a narrower response in a templated format, which can be transformed into a structured format (e.g. JSON).
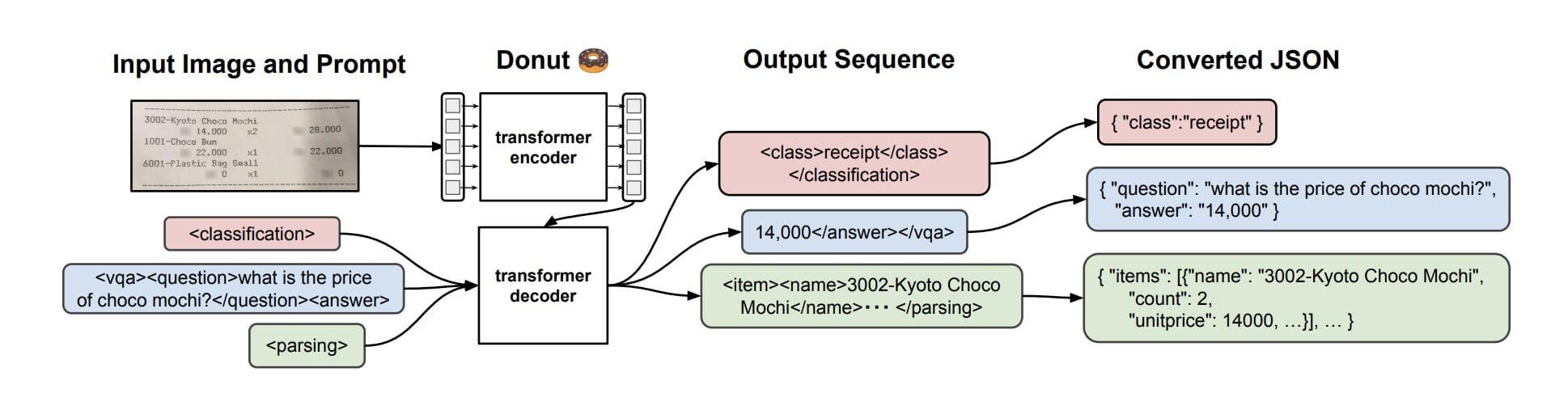
Similar to recent multi-modal LLMs, the Donut model takes an image and prompt as input, and returns an output sequence as a string, which can then be converted to a standard JSON output. And because the same model performs these operations, it provides additional flexibility to our ML pipeline.
Unlike previous document understanding models, Donut’s ability to process raw documents without pre-processing reduces the potential for cascading failures and a complex system design that often leads to product support challenges for users. The simplicity of the architecture is not only a boon for product ease-of-use, but also has demonstrated speed-ups in processing time based on internal benchmarks.
Try it Yourself
We’re excited to see how this new feature helps organizations deploy new use-cases for passports, checks, driver’s licenses, and invoices. If you’re in need of fast processing times, a simple easy-to-use extraction product, and don’t want to deal with a complicated set-up, we’d love to collaborate with you.
We are actively building a roadmap for other OOTB models and would love to talk to you about what you would find useful and how you see yourself using these models. For current Hyperscience users, we can provide access to a web demo where you can upload samples and try it for yourself. To explore how these models can speed up your document processing operations, please contact us here and request more information.
