
Sr. Machine Learning Engineer Arnaud Stiegler Shares His Experience
How it Started
Hackathons are both taxing and thrilling for any engineer. They involve working quickly and efficiently to achieve as much as possible over a short period of time. They require complete commitment for a few days, but they also provide the opportunity to try out an exciting new idea or to experiment with new technology. To make a Hackathon worth the effort, we always try to find exciting ideas that can transform some aspect of our product.
Toward the end of summer, a recent study piqued our interest. Titled OCR-free Document Understanding With Donut, it introduced a ground-breaking model that radically changes how document processing is done.
Whereas the typical document processing pipeline involves many different machine learning models (more on this later), this new model (called “Donut”) processes a document end-to-end in a single pass. Excited by the prospect of trying it out and testing it with our own intelligent document processing (IDP) platform, we decided to form a hackathon team and see what this new model is all about.
A Major IDP Challenge
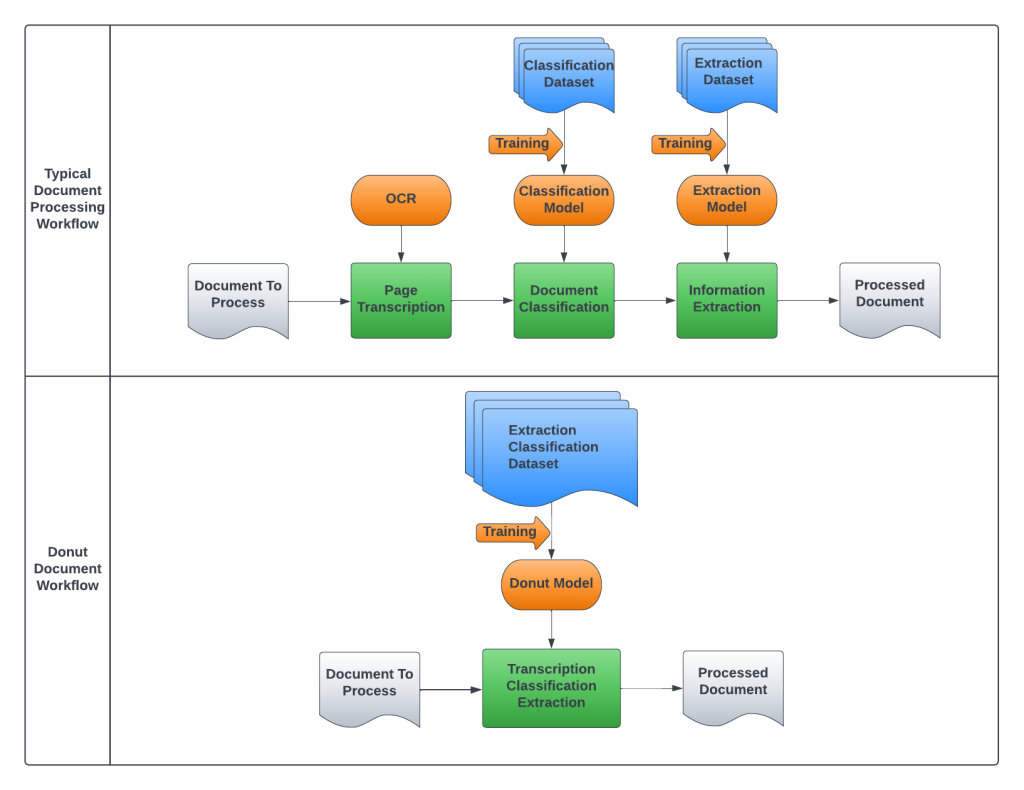
The current state of document processing is that the processing pipeline relies on a cascade of machine learning models. First, you transcribe the content in a document from the image using a process called optical character recognition (OCR). Then, you classify the processed image by placing it in a category. Finally, you extract the relevant data for use in other systems.
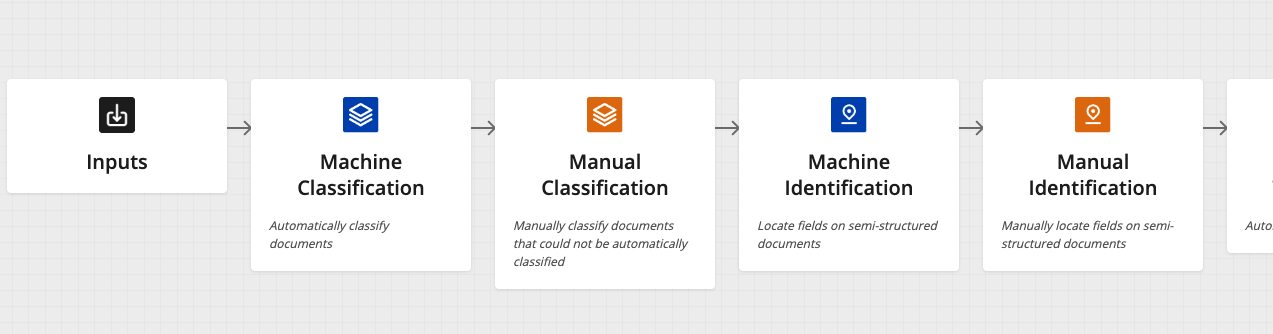
These three steps require multiple machine learning models to process a document end-to-end. Furthermore, current extraction models are usually trained for a specific set of fields and a specific type of documents—the more document types there are, the more extraction models required. As a result, the pipeline for processing multiple document types increases in complexity.
There are several drawbacks for using multiple models, including:
- Compounding Model errors: If model A makes an error, that error will be passed onto model B, which in turn is likely to introduce additional errors
- Model management overhead: Each model must be trained independently along with the overhead of having to manage them—this is a significant resource drain
- Processing times: Multiple models can mean more latency, equating to more work to optimize for processing speed
The goal of our project was straightforward: could we unify all those models into one, and therefore have a one-model end-to-end pipeline for document processing?
Framing Our Hackathon Project
We focused on two main questions for our project:
- Can we prove the validity of our approach for real-world use cases that our customers face?
- Can we demonstrate those new capabilities within our product?
At its core, the first question is a machine learning problem. A recurring issue in the document processing space is a lack of real-world, open-source datasets. Complexities like blurry scans, handwritten text, difficult document types, complex extraction tasks, and more contribute to real-world issues with document data, and these imperfections aren’t found in common open-source datasets. Part of our project was to make sure that the model we wanted to use performed well with those cases.
Moreover, although information extraction capabilities had been benchmarked in the original article that caught our attention, combining document classification and extraction across many different document types wasn’t part of the publication. Therefore, we had to validate the assumption that the model would be able to learn to process different document types and a vast array of fields.
To answer the second question, we focused on creating a compelling story that shows how the project could have a real impact on customers. That meant crafting a challenging and realistic set of documents to process, and get the whole pipeline in our IDP platform. The whole demo would be about showing what this new model would mean for our customers.
The Hackathon Experience
Since our team was based in two different time zones (New York and Sofia), we organized work so that we could get to the training stage as quickly as possible—we wanted a fine-tuned model to present in a live demo. Using our internal ML tools and a good dose of teamwork, we quickly set-up and fine-tuned a model, and then achieved our first milestone: observing the end-to-end performance of the model. Results were satisfactory, providing clear evidence that the Donut model could be used for real-world use cases.
Once training was finalized, we spent our remaining time creating a demo to showcase the model in our Hyperscience app. Thanks to the flexibility of our Flows SDK, and through a hosted API endpoint, we replicated a typical IDP flow with OCR, document classification, and field extraction using our single unified model. In practice, we were able to get rid of many of the building blocks that would have been otherwise needed for the workflow.
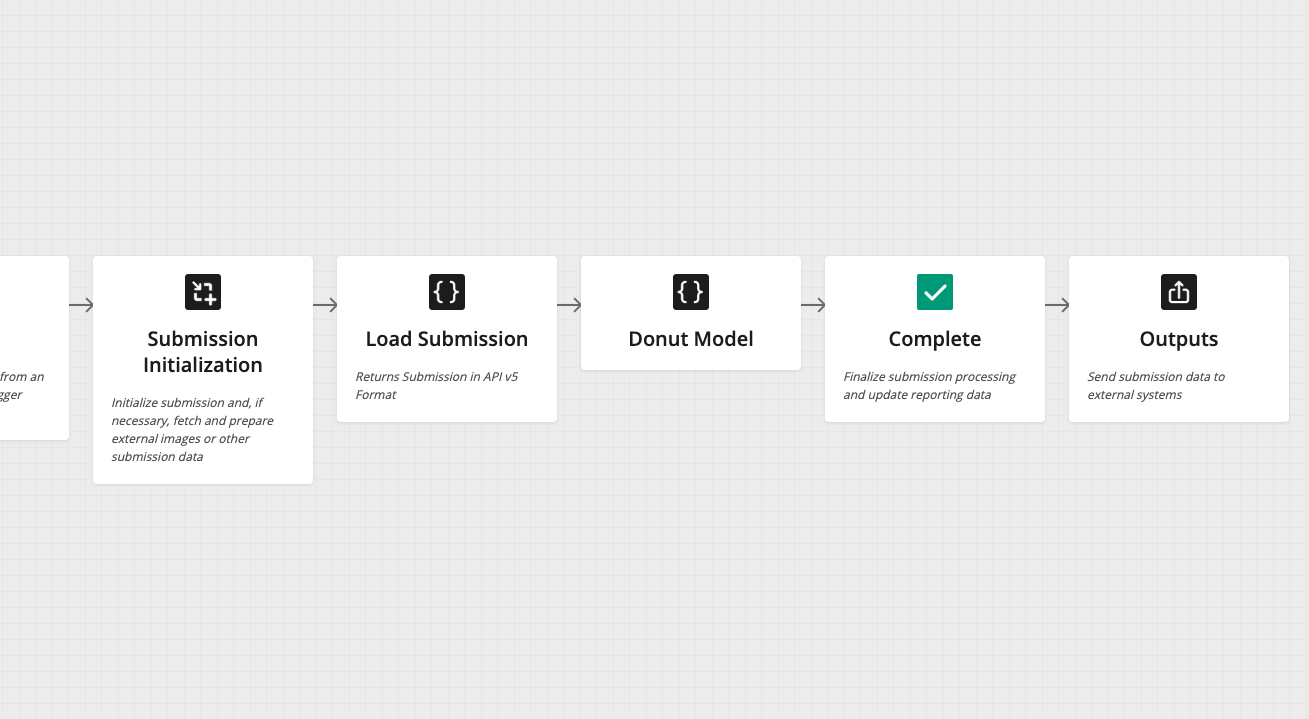
What would that mean for end-users? Training and managing a single ML model results in a faster, lighter, and more straightforward end-to-end document processing pipeline.
Getting Technical: The Donut Model Explained
I mentioned the Donut model above—let’s take a closer look at how this model informed our hackathon project.
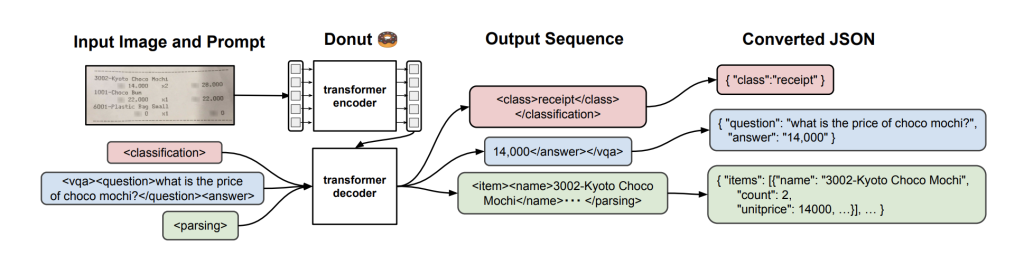
The Donut model is an encoder-decoder transformer-based model with:
- Encoder: a Swin transformer that takes an image and generates a latent representation of that image
- Decoder: a Bart-based decoder that takes the latent representation and generates a plain text output
Thanks to this architecture, the model is capable of reading a document, finding the relevant information on the page, and transcribing it. In practice, that single model replaces the typical OCR + Extraction model combo that requires chaining multiple models.
Some key elements stand out from the article that caught our attention:
- Contrary to other document understanding models, this model is pre-trained on a transcription task
- It uses a similar paradigm to T5, where all tasks are framed as seq2seq tasks whether it is Extraction, Question Answering, or Classification
- The model returns a text output that corresponds to either a label (for classification) or a transcription of the answer (for Extraction and QA)
Adapting Donut to Our Document Processing Use Case:
To unify our cascade of models into one, we had to modify the model so that it:
- Combines the document classification task with the extraction task
- Filters out the extraction results based on the classification prediction (since we expect different fields for different document types)
- Accepts a unified classification+extraction dataset that mixes different types of documents with different sets of fields
What Did We Learn?
The reason we entered the Hackathon in the first place was that everybody in the team was excited to show this new model to our colleagues. After the presentation, there was quite a bit of conversation about it not only from the technical side but also from the go-to-market side. Everybody was (and still is!) very excited about the Donut model, and its potential implications for the way we process documents.
On the technical side, we’ve only scratched the surface—there are still unanswered questions such as:
- How good is the transcription on difficult documents (such as checks) compared to a specialized OCR model?
- To what extent can we scale the dataset to incorporate more fields and more document types?
- How do we integrate our human-in-the-loop component (that asks for human input when needed) into a model that combines all tasks?
I’ll close by thanking my teammates—a big thank you to Ceena Modarres and Daniel Balchev for all their help with this project. Moving forward, we truly believe in the potential of this approach, and will further investigate how to get this model to production.
