
Example of email classification by sentiment.
In today’s data-driven world, businesses are constantly looking for ways to extract meaningful insights from their data. However, a significant portion of enterprise data is unstructured, making it difficult to analyze and organize. To help businesses unlock the potential of their unstructured data, Hyperscience has released a new feature: Text Classification.
With this release, Hyperscience is enabling businesses to make impactful changes to their business processes that will ultimately help their customers.
What is Text Classification?
Text Classification helps businesses train models to classify unstructured data in documents, emails, and more. Once the data has been classified, Text Classification allows users to analyze the data by user intent, sentiment, topic, or any custom labels based on their own business rules.
For example, you can use the Text Classification feature to:
- Classify the medical disorders listed in a patient intake form
- Determine the sentiment expressed in a customer comment and apply a label to it (e.g., “positive,” “negative”).
- Categorize and prioritize emails by customer intent (e.g., inquiries, complaints, requests to change account information).
How Does Text Classification Work?
With Text Classification, Hyperscience provides a workflow block that you can use to classify the text extracted from a specific field, document, or email.
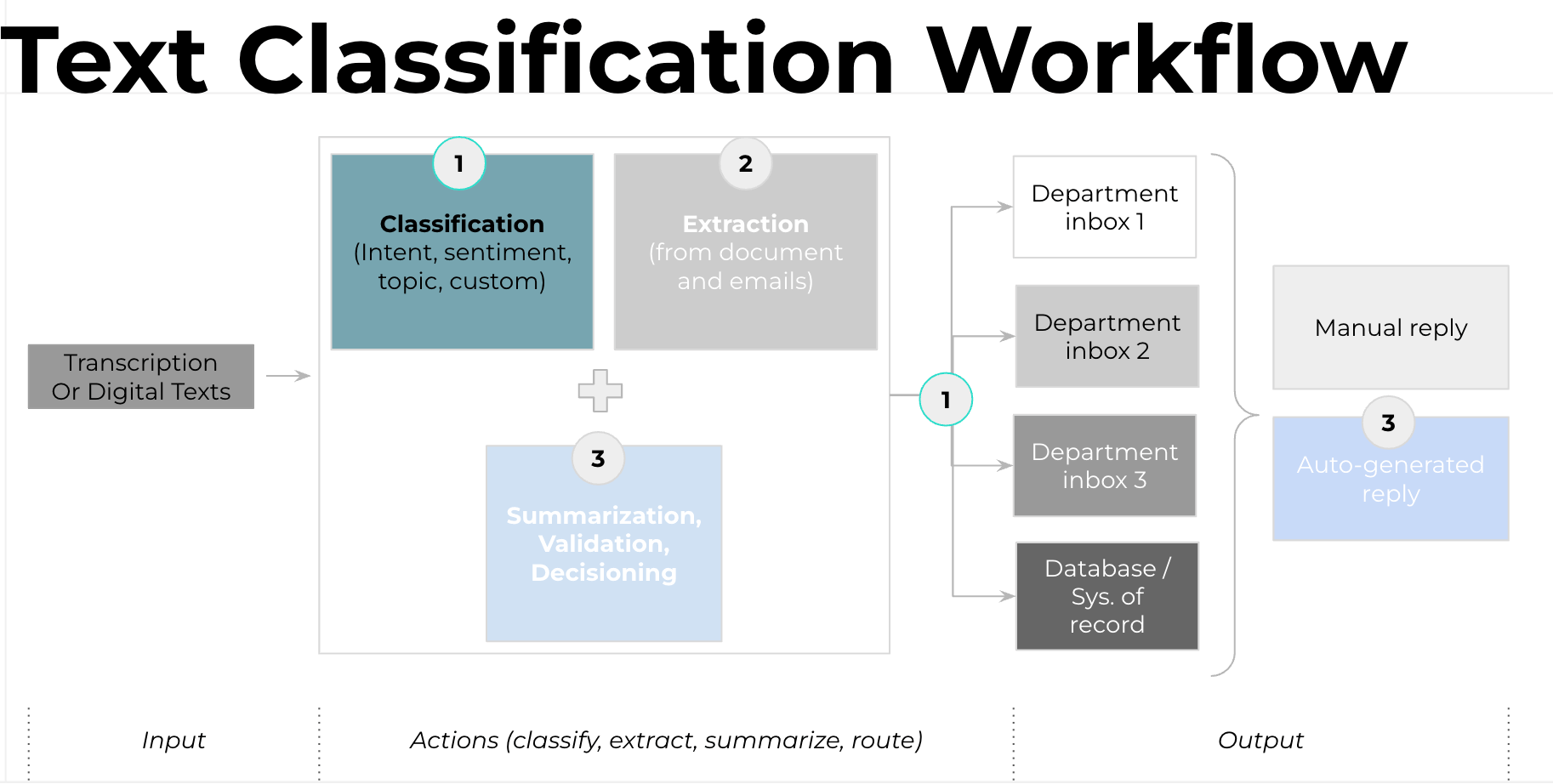
A view of a complete email processing workflow
What are the Benefits of Text Classification?
Text Classification is a key component of intelligent document processing (IDP) providing several benefits that can help businesses improve their document processing capabilities. Some of these benefits include:
- Increased Accuracy: Text Classification can accurately categorize and extract data from unstructured documents, reducing errors and improving data quality.
- Time-savings: Text Classification can automate the sorting and routing of documents, allowing employees to focus on higher-value tasks that require human intervention.
- Improved Efficiency: By automating document classification, businesses can increase processing speed, reduce manual intervention, and improve overall workflow efficiency.
- Enhanced Compliance: By accurately categorizing and extracting data, Text Classification can help ensure compliance with regulatory requirements and internal policies.
- Improved Customer Experience: By automating document classification and extraction, businesses can reduce processing times and improve response times, leading to a better customer experience.
Businesses using the new Text Classification feature will also discover insights hidden in unstructured data. For organizations seeking a leg up on the competition this feature offers the functionality needed to maintain a leading edge.
Text Classification Use Cases:

Text Classification has numerous applications in various industries, including insurance, finance, and public sector. Here are some of the text classification use cases in each of these industries:
Insurance:
- Claims Processing: Classifying claims documents into categories like motor, health, property, or accident
- Underwriting: Classifying customer applications for insurance into categories like high-risk or low-risk.
- Fraud Detection: Classifying claims documents and transactions as fraudulent or non-fraudulent based on past fraud cases.
Finance:
- Customer Service: Classifying customer inquiries into categories like billing, account management, and support.
- Investment Management: Classifying financial news articles into categories like stock prices, company announcements, and market trends.
- Compliance: Classifying financial reports and documents based on regulatory compliance requirements.
Government Agencies/Public Sector:
- Public Safety: Classifying emergency calls into categories like fire, police, and medical services.
- E-governance: Classifying citizen complaints, requests, and feedback into categories like water supply, electricity, and transportation.
- Social Media Monitoring: Classifying social media posts and comments based on sentiment analysis to gauge public opinion on government policies.
In each of these industries, Text Classification can help organizations automate document processing, save time, and improve accuracy. By leveraging AI-powered Text Classification, organizations can enhance their workflows and provide better customer experiences while reducing costs and errors.
Get Started with Text Classification
Text Classification is available now in the R36 release of Hyperscience. With this feature, users can easily categorize and label text data, improving accuracy, efficiency, and ultimately, customer satisfaction. To see a demo and learn more about how your business can benefit from Text Classification, contact us here. For a closer look at this feature, read our technical documentation here.
