
In December, Hyperscience launched Named Entity Recognition (NER), an out-of-the-box natural language processing (NLP) machine learning (ML) model, that allows customers to extract entities such as addresses, person names, locations, organizations, and companies from free-flowing text. Hyperscience customers can now extract personal identification information (PII) entities from any document without having to pre-define a field list or train an extraction model.
What is Named Entity Recognition?
The NER model is pre-trained by Hyperscience to extract entities from unstructured documents. In this case, an entity is defined as a grouping of values or fields into a given class, such as names, addresses, and more. The NER model is currently pre-trained to recognize person names, organization/company names, and addresses. NER is, put simply, an out-of-box model at the field level.
The Custom Entity Detection model (CED) block, that is to be launched soon, provides a complementary function to the NER model by detecting and extracting out-of-the-box words or word patterns that can be described with a combination of regular expressions (regexes) and keywords. At launch, a default list of regex types and keyword types will be pre-trained by Hyperscience for the CED block. Used together, NER and CED provide customers the ability to identify and extract commonly used named entities from a text segment.
How Does Named Entity Recognition Work?
The NER block works along with Full Page Transcription (FPT) and can be used to enhance the FPT output with additional information for further processing. In the example shown below, a custom FPT flow is used to extract names (“James Mullins”, “Kimberly Kidd”), organizations (“Innovative Pocket LTD”), and addresses (“351 Jack London Ave Alameda, CA 94501, USA”) from the sample document. These extracted values can be used by a downstream NLP model to replace these values or for lookup purposes.
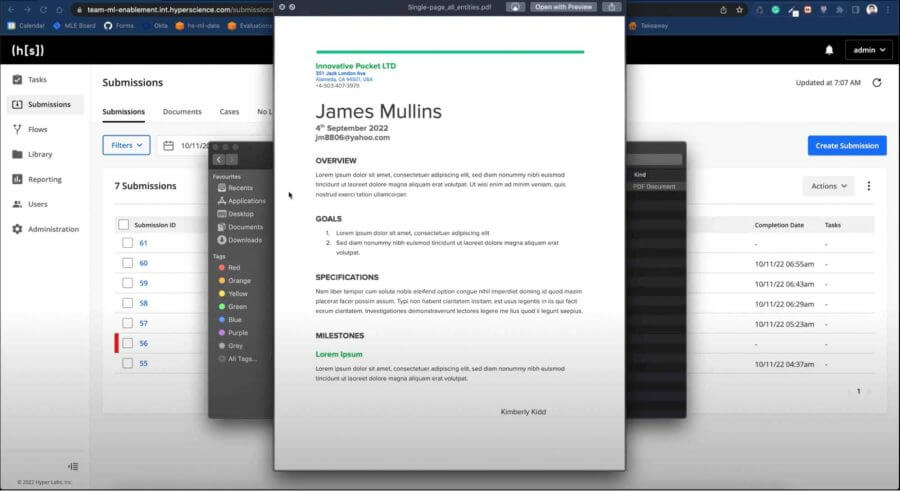
The FPT block is a prerequisite and should run before the NER block in this custom flow.
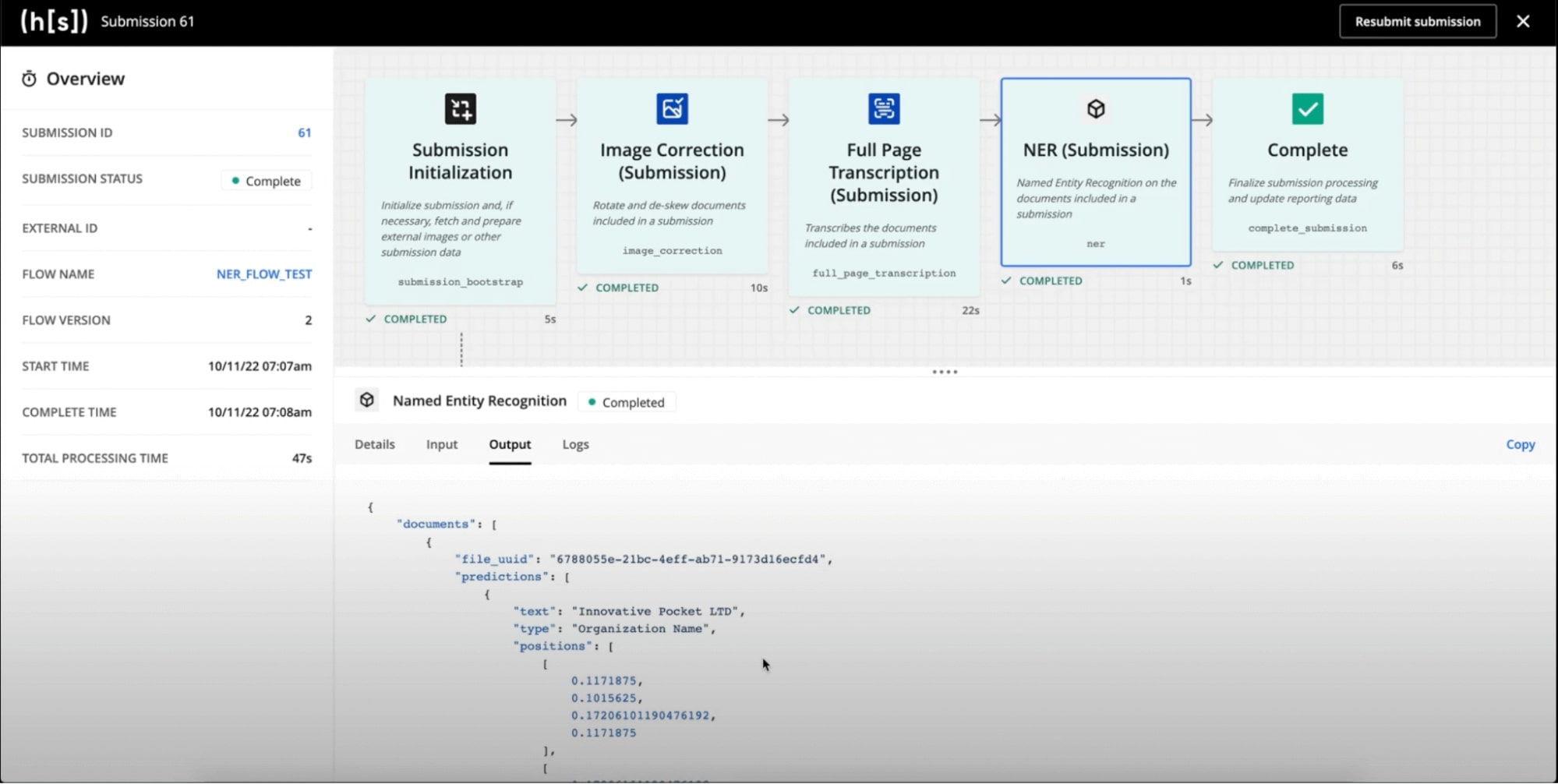
The NER block can also be used with the custom entity detection block in custom code for extracting pattern-based values like account number, phone number, SSN etc.
What Entities are Currently Pre-trained by NER and CED?
The NER model is currently pre-trained to identify and extract: person names, organization/company names, and addresses.
The CED block will be pre-trained at launch for the following regex types:
- SSN
- employer id
- US phone number
- date
- MICR
- machine readable line
The CED block will also be pre-trained at launch for the following keyword types, including:
Date, SSN, address, policy number, loan number, credit card number, customer id, account number, employee id, employer id, passport number, USCIS number, driver license restrictions, driver license number, I94 number, pin number, PTIN number, judgment number, case number, bankruptcy number, US phone number, application number, file number, routing number, NMLS number, appraiser certification number.
Not seeing an entity that should be on the list? We are constantly looking for feedback from you to add to the list of supported entities.
Why Use Named Entity Recognition?
NER, together with CED, can be used in a variety of customer use cases, and offers several benefits, including:
- Extract Personal Identification Information
Customers can use the NER block to extract the most common PII entities as part of their redaction pipeline or to comply with legal requirements. For example, you can build a redaction flow that processes documents through full-page transcription, then detects all personal names, and at the end uses a custom code block to put black boxes over the detected names. - Supplementary Document Review
Many document heavy processes rely on supplemental documents and forms. Take the mortgage approval process, for example. In this use case, NER can be used to identify parties in a transaction document, speeding up the approval process. - Data Validation & Verification
Similar to the above, NER can be used to verify that entities remain consistent across all submitted documents. For example, with NER, an insurance company can certify that accident dates are the same across all pages when reviewing the supporting documents submitted with an insurance claim. This ensures that all extracted data is accurate and consistent. - Fraud Prevention
NER can be used as part of the fraud prevention subsystem to look for and blacklist specific entity names, organizations, or companies in the audit system. Identifying fraudulent information keeps data secure, minimizes risk, and protects company assets.
How can You Get Started with Named Entity Recognition?
The launch of Named Entity Recognition marks a significant milestone in our goal to help customers bring any document to Hyperscience. We aim to help companies integrate and scale ML technologies across their business and drive value from ML investments faster by empowering all users, regardless of technical background, to easily build and integrate ML solutions into their workflows.
This feature is available now, and Hyperscience customers can get with it by reaching out to our customer success team to upgrade to the latest version. To see a demo and learn more about how your business can benefit from Named Entity Recognition, contact us today.
