
Train Quality Machine Learning Models in Less Time, with Fewer Samples
With Hyperscience’s newest product release, we’re excited to announce the launch of Guided Data Labeling. Guided Data Labeling brings a new set of automation tools to the platform to create a faster, smoother experience for gathering and annotating training data. With this new feature, customers can accelerate time to value by training machine learning models faster—no technical expertise required.
Why Use Guided Data Labeling?
Quality data is key to building a high-performing ML model. After all, a machine learning model is only as good as the data used to train it. Unfortunately, establishing a quality training dataset is challenging, as it requires a continuous loop of trial and error.
This challenge is further complicated by the lack of quality training data. ML models require significant training data to perform effectively out of the gate, but companies often don’t have the required amount of data to train a new model effectively. Additionally, the time-consuming, monotonous process of labeling training data often results in poor quality and inconsistent data sets that hurt model performance.
How Guided Data Labeling Works
To ease the model training burden, Hyperscience empowers customers to navigate this error-prone process with a simple point and click interface.
With Guided Data Labeling in Hyperscience, organizations get access to automated guidance and tailored tips on:
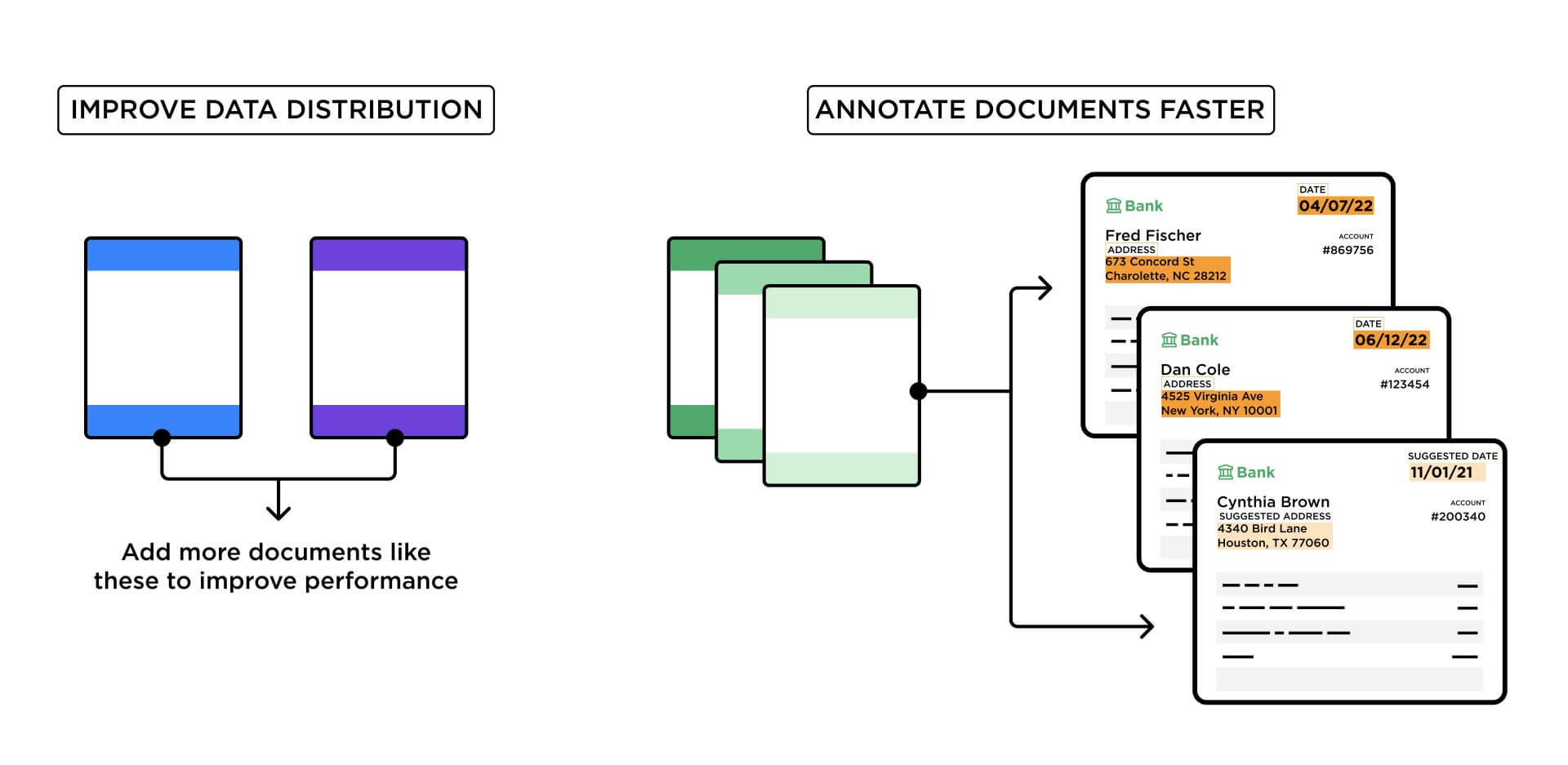
- Improving Data Distribution: Create a diverse, representative training dataset for specific use cases to optimize model performance
- Annotating Documents Faster: Label documents with the help of automated suggestions after as few as 2-3 documents to help speed up the data labeling process without compromising accuracy
Key Benefits
These new tools help customers improve training data distribution by suggesting which documents should be added or removed, optimizing model performance and reducing annotation time and effort.
The primary benefit of this feature is that it helps businesses get started processing documents with an accurate model more quickly. By decreasing the training period, organizations can deploy a fully-trained ML model in production environments sooner—shortening the time-to-value period of the solution. This is further enhanced by how easy to use the feature is—enabling more users without strong technical skills to accurately train ML models.
How to Get Started
This launch marks a significant milestone in helping enterprises scale the adoption of ML technology across their business and drive value from ML investments faster by empowering all users, regardless of technical background, to easily build and integrate ML solutions into their document processing workflows.
This feature is available now, and Hyperscience customers can get started using it by reaching out to our customer success team to upgrade to the latest version. To see a demo and learn more about how your business can benefit from Guided Data Labeling, contact us today.
