
or: How We Ended up Writing Our Own Workflow Engine
Creating a workflow engine from scratch requires extensive planning and the dedication of valuable internal resources. Several commercial and open-source workflow engines are readily available, so why would a company that’s not in the business of writing workflow engines decide to do so? Is the effort—and the associated costs—worth it?
In this blog post, we’ll explore Hyperscience’s main use case and the platform that facilitated our Intelligent Document Processing (IDP) solution. Then, we’ll explain how our customers’ requirements led us to re-think our platform, and ultimately, implement our own workflow engine. We’ll end with a look at how our workflow engine has benefited both our customers and our organization.
If you’re a software engineer, product manager, or student interested in IT, you may find our learnings helpful as you decide whether or not to create a workflow engine of your own.
What Were We Solving For?
Hyperscience has always strived to provide a machine-learning platform that enables enterprises to easily deploy and make use of the advantages that AI can provide to their organizations. The primary use case that we have been focusing on in recent years is Intelligent Document Processing, or IDP.
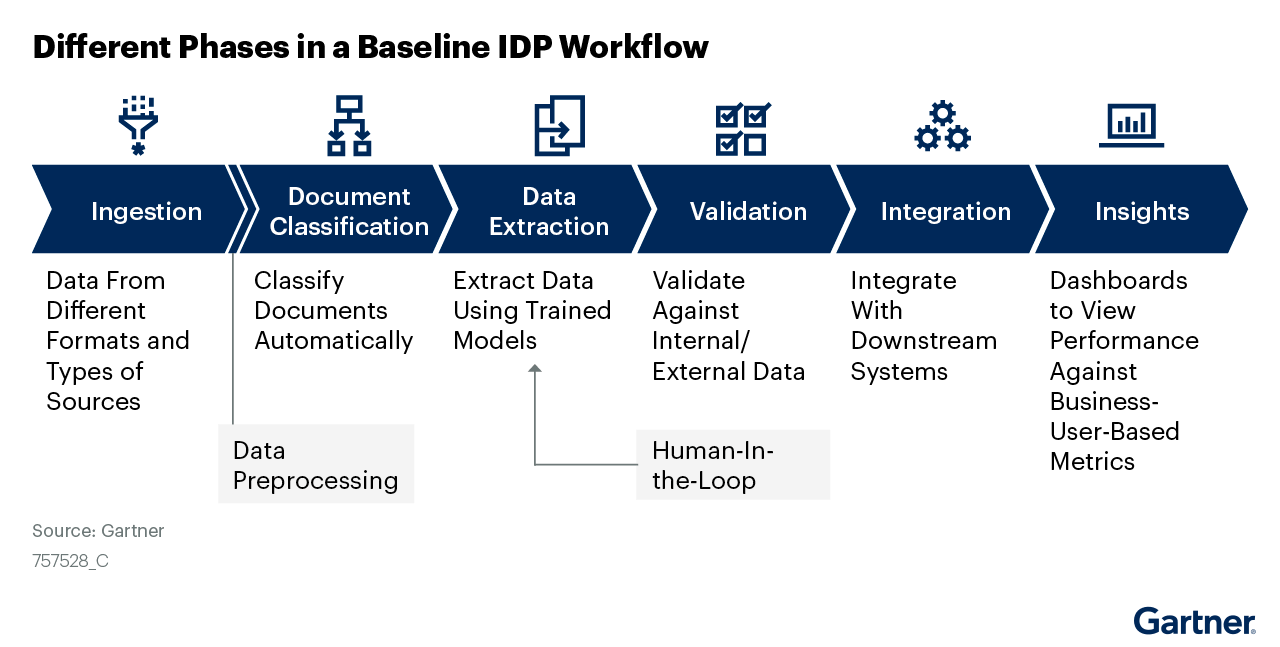
In the past, document processing products were focused on something more akin to “document cataloging,” where scanned documents are indexed alongside some metadata. Advancements in optical character recognition (OCR) allowed these solutions to also extract text and provide text-searching and summarization capabilities. Hyperscience’s award-winning solution goes one step further, making it easy to extract structured data from documents, even if the data is handwritten or is submitted on crumpled paper.
How it Started: Our Initial Architecture
To facilitate the IDP process itself, our architecture initially looked something like this:

When distributing workload across multiple worker services, a fairly standard solution is to use some sort of a job queue, where individual services can dequeue tasks, work on them, and schedule the next tasks when they are done.
In our IDP workflow, a document comes into the system, and the backend schedules the first task (e.g., classification of the document). Once the task is completed, the classification service decides whether to follow up with a human supervision task if the confidence was low, or to proceed directly to a text extraction task.
This solution worked well for us, as it allowed us to track progress (the job queue itself), with the slight drawback that services were semi-coupled, as a service needs to know “what comes next” so that it can schedule a task when it’s done with its job.
As it eventually happens with any project that is used in production long enough, business requirements started demanding outcomes that the existing architecture struggled to deliver. While task distribution and horizontal scalability were never a bottleneck of this design, making slight changes to the process itself was very difficult. If customers wanted to customize the process in any way, they needed to implement those customizations externally and apply them to their documents before or after they were sent to Hyperscience. Making any changes to the document-processing pipeline itself would have required a code change, a patch release, and delivery to each customer, as some customers install the Hyperscience Platform on-premise—sometimes in entirely offline environments.
Complicating the situation further, some requested features simply did not make sense for the product as a whole, although they were very beneficial for a particular client.
In short, we needed to introduce a scalable way to extend the processing pipeline and allow for customizations.
The Solution: Workflow Engines and Service Orchestration
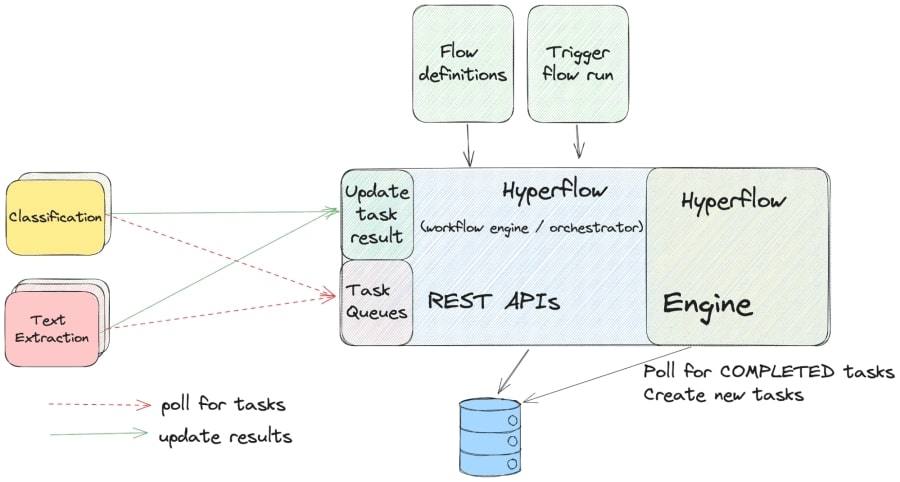
That’s when we rolled up our sleeves and started researching alternatives. Discussing all possible solutions is worthy of another blog post in and of itself, so in the interest of keeping to the point—we eventually settled for the workflow engine architecture, using a workflow orchestrator.
In reality, this architecture is quite similar to the message queue architecture, as separate services still poll for tasks. This setup makes it easy to add additional instances of any of the services for the purposes of horizontal scalability. The primary difference is that now there is an actual service—the workflow engine—that handles the details around what work needs to be scheduled.
Available Workflow-Engine Solutions
Dedicating engineering time to writing “yet another” workflow engine can be an expensive endeavor. It can be particularly resource intensive for companies that aren’t in the business of creating workflow engines, especially considering that a number of off-the-shelf solutions already exist. Here some examples that you can investigate if you would like to give workflow-service orchestration a try:
– Netflix Conductor
– Amazon SWS
– Temporal
– Apache Airflow
– Azkaban
So, given these circumstances, how did we end up developing Hyperflow—our own workflow engine implementation?
We embarked on the journey to find a suitable workflow engine back in 2020. We had several customers who operated in “air-gapped” environments without internet access, so any engines requiring an internet connection would not work. Others were dropped from consideration because they worked with code-based definitions. We were looking for the flexibility afforded by blueprint-based definitions, which would give us more options in how those definitions were written (e.g., code-based SDK or visual wiring).
And that’s how we ended up with Netflix’s Conductor. It covered all the baseline requirements we had, and outside of some very minor details, it was a great match.
We started a pilot adoption of Conductor across our SaaS infrastructure. However, for on-premise-based deployments, provisioning additional storage infrastructure was a non-starter. Part of what makes Hyperscience simple to operate for some of our customers is that the platform itself has fairly barebones requirements: a relational database (PostgreSQL, Oracle, or MSSQL) and an image store. While this system architecture presents some limitations, it greatly simplifies the operational complexities that come when dealing with stateful infrastructure.
This led us to our second journey: writing a tiny API-compatible implementation of Conductor to serve on-premise customers.
The idea was simple enough: support the core functionality needed for processing while keeping all the “bells and whistles” available on our SaaS instances where the fully-fledged Conductor was deployed.
We started coding, but quickly realized that there were some major drawbacks to supporting both Hyperflow and Conductor.
For starters, engineers needed to keep in mind both systems when developing new features or troubleshooting client issues. When releasing new platform versions, we also had to run all of the higher-level functional and load tests against the system with both orchestrators to make sure we were not bottlenecked on one of the implementations.
Evolution-wise, we were also in a place where new features had to be implemented for both Hyperflow and Conductor, and that was without going over the details of “what if” we introduced a breaking change that the maintainers of Conductor were not interested in adopting. If that had happened, we would have had a forever-fork that would’ve required separate maintenance.
That’s how, shortly after its inception, all internal teams adopted Hyperflow across all installations, and we dropped the requirement for API compatibility. What started out as a tiny implementation serving the core workflow engine functionality became a fully-fledged service orchestrator that powers the Hyperscience Platform.
Parts of the Hyperflow Solution
A few components make up the overall Hyperflow solution, which are fairly common among other similar workflow systems:
- Flow definition: the “blueprint” defining what tasks are to be executed and in what order
- Blocks: definitions of individual tasks or services
- Workflow engine: the orchestrator that keeps track of individual flow runs, progresses them, manages the fanning out concurrent tasks, retries failed tasks, and so on
- User Interface (UI): brings all these parts together for users
Let’s take a look at each one in more detail.
Flow Definition
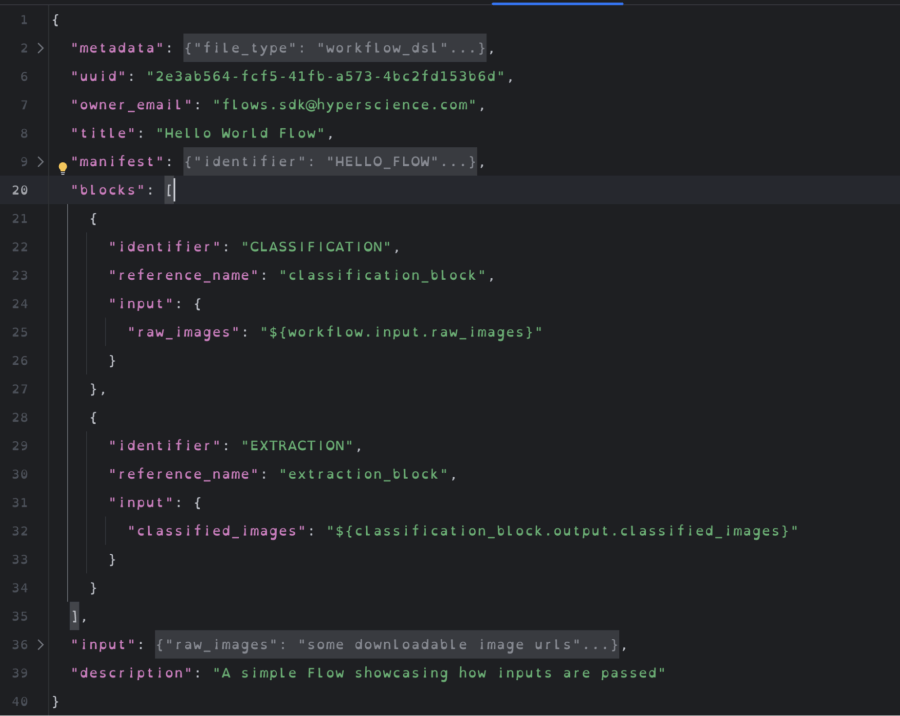
The flow definition is a JSON-based blueprint that contains metadata about a particular workflow, or flow. More importantly, it dictates what tasks should be executed in the flow, in what order, and how their inputs and outputs should be wired together.
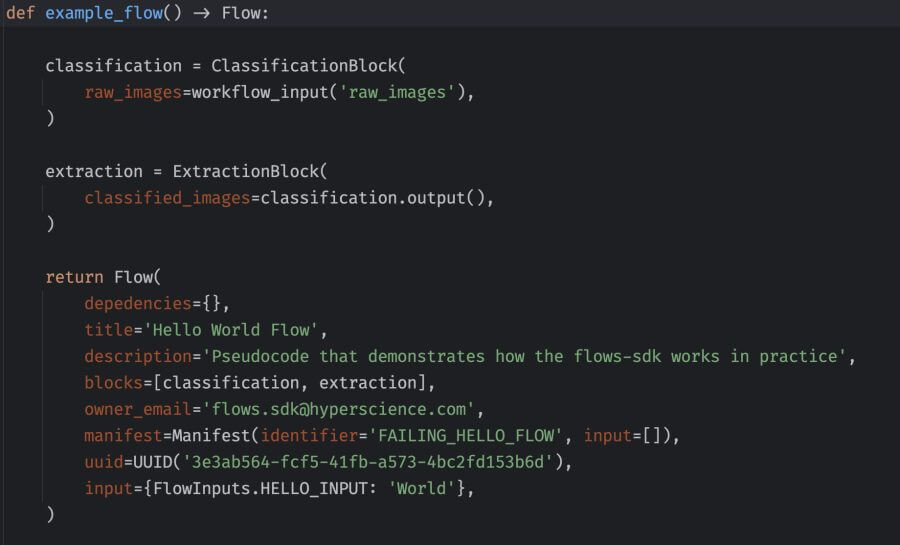
While we could have implemented flow definitions as code, we opted for a language-agnostic, blueprint-based approach because it provides greater flexibility in how we generate them. Currently, the main way of creating flow definitions is by using a Python-based SDK. We decided on Python as our first SDK language after research into our internal and external users revealed that both sets of developers had an overwhelming preference for Python. Even so, our commitment to a blueprint-based flow definition allows us to easily create SDKs for other languages or even a UI builder if it makes sense for the business in the future.
The screenshots below show a sample JSON flow definition and the Python code that generated it.
Blocks
We opted to call our service executables “blocks.”
Each block consists of two parts:
- A manifest, or a lightweight descriptor containing metadata like the block identifier, expected input types, and programming language version and runtime
- The actual implementation, or code, of the block
Additionally, there are two types of blocks, differentiated by their implementations: system blocks and external blocks. For a developer writing a flow, the distinction doesn’t matter, as all blocks are “chained together” the same way. However, there are some considerable differences in how system blocks and external blocks are managed and executed.
System blocks are run in-line directly by the workflow engine, and they are usually cheap and quick to execute. We incorporated them into the system because we expect them to have a very long shelf life, as system concepts tend to be hard to deprecate.
Examples of system blocks include the following:
Lambda: Blocks with custom code in the form of a Python lambda expression (e.g., expressions that perform simple data transformations)
Decision: The flow equivalent of a “switch” statement
Fork: Parallelization of block executions that are later joined together
External blocks are programming language agnostic. For our non-Kubernetes on-premise deployments, they are managed by a custom “block process manager” solution that is responsible for launching the blocks required by the particular deployment, depending on what flow definitions are running on that system. For Kubernetes-based deployments like those provided by our SaaS offering, we’ve implemented a Kubernetes operator that performs a similar job, only it manages the blocks as pods instead of processes.
Some examples of external blocks include the following:
- blocks that use an embedded ML model like Visual Classification or Text Extraction
- Input and output connectors like a Kafka consumer/producer block or an email listener
- Python code blocks that allow flow developers to import third-party Python libraries and write more involved code compared to the Lambda blocks mentioned previously.
Workflow Engine
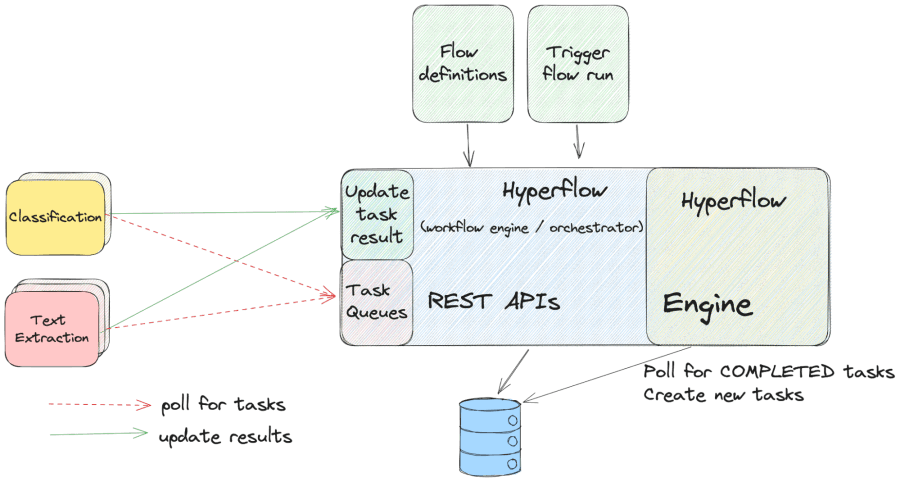
Workflow engines like the one we implemented can be thought of as “smart state machines” that combine the blueprint (flow definition) with the current execution state (individual flow run) in order to schedule tasks, maintain the execution context for the particular flow run, and update the flow status.
The Hyperflow workflow engine has two main responsibilities:
- Versioning and storing flow definitions (the blueprints)
- Example: In cases where a flow has already started its execution, but its definition was updated, we need to know the pre-update version in order to facilitate the flow runs that are already in progress.
- Scheduling tasks (for the blocks to execute) and keeping track of the running state
- Example: A block polls for tasks, finds one, executes it, and updates the workflow engine with the result. Then, the workflow engine needs to decide what task to schedule next and then schedule it with the required input.
It also completes many other tasks, like offloading large execution contexts to an image store in a manner that’s transparent to the blocks, handling retries and failure scenarios, and submitting various observability metrics.
User Interface
A workflow-engine solution would be incomplete without a UI that helps users manage flow definitions (e.g, import, export, and configure flows), track flow progress, and debug failed flow runs.
Two examples of platform pages dedicated to flows are shown below.
Flow Runs: The screenshot below shows a list of flow runs and offers useful filtering based on criteria like status or correlation ID. System Admins can use this page to find more detailed information on the execution of specific flows and, in the case of flows that consist of subflows, their related flow executions.

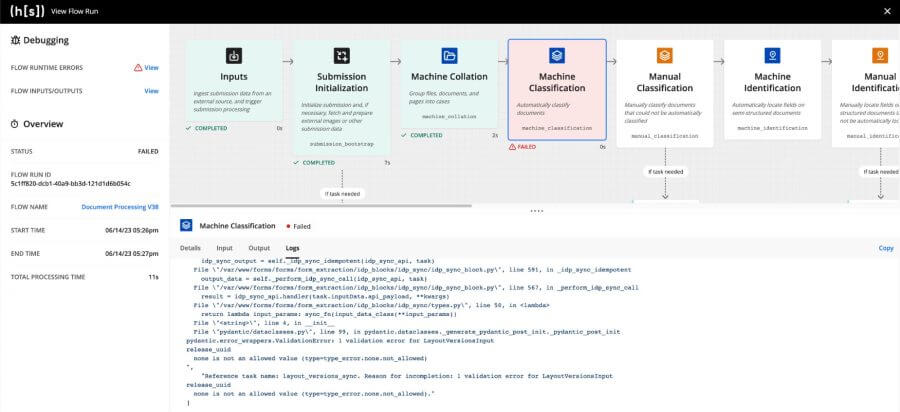
View Flow Run: This page shows all the blocks that have been executed in a flow, alongside details like the time it took for the blocks to run, their inputs and outputs, and, in the case of failure, stacktrace or other error logs from the failed block.
Does it Work?
To give you a sense of how our solution can scale, here’s what one of our larger deployments looks like:
- 50 Amazon Elastic Compute Cloud (EC2) m5.4xlarge instances*,
- for a total of 800 CPU cores
- and ~3000 GiB RAM,
- backed by a db.m5.8xlarge database with 15k input/output operations per second (IOPS) storage
…resulting in a throughput of about 10 million daily flow runs.
* Most of the cluster compute resources are consumed by the processing-heavy ML blocks.
Re-platforming an application is rarely trivial, and our journey so far surely hasn’t been. So was it worth it?
The generic, “out-of-the-box” IDP solution met the needs of about half our customers. For them, the entire effort may have gone unnoticed, aside from the fancy new UI pages that showed up for them in the platform. For the other half, though, the new architecture has been a great success—it’s allowed them to complete tasks ranging from minor data validation to new, fully fledged use cases that we did not even think possible. People come up with creative use cases when you give them the right tools!
Internally, teams have also demonstrated many innovative uses of the new platform. Some of my personal favorites include the following:
- Adding sound to the platform inputs, allowing for more modalities than just documents
- Implementing the engine on top of a message queue. This project solidified our confidence that the system interfaces are sufficiently stable, while also offloading the database to allow for an even higher (and faster!) throughput.
- Teaching a large language model (LLM) how to customize flows and implement custom functionality
As for the future, the team is busy at work with all sorts of improvements to our current solution, such as:
- Making it easier to connect multiple flows together (flow groups)
- Enhancing the View Flow Run experience to facilitate easier testing and debugging of flows (especially important during major platform upgrades!)
- Adding more customizable retrying and error-handling capabilities
In Summary
The decision to write our own workflow engine was not one we took lightly. In fact, it wasn’t our first choice! However, no existing solution worked within the infrastructure limitations of on-premise deployments. As we faced the challenges of maintaining separate workflow-engine solutions for our SaaS and on-premise customers, the need to create our own workflow engine became apparent.
Not only did Hyperflow allow us to meet the requirements of all our customers, but it also expanded the capabilities of the Hyperscience Platform. Creating a workflow engine from scratch may not be worthwhile in all situations, but in ours, it definitely was. Hopefully our story will be useful to you if you need to make a similar decision.
